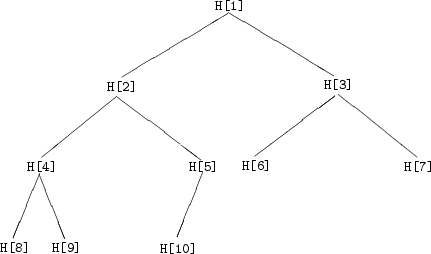
ヒープは、ソーティングの高速化のために、J.Williams [178]によって発 明されたデータ構造であり、一次元の配列の中に木構造を埋め込んだデータ構造をし ている。ヒープを使うことによって、ソーティングのアルゴリズムは、通常の木ソー ティングアルゴリズムに比べ大きく改善された[179]。
ヒープは、以下に示すような制約条件を満たす一次元の配列として定義される。
| (190) |
| (191) | |||
| (192) |
ヒープの特徴は、二分木で表現した時、木の根の要素、つまり ![]() が最小値とな
ることである。ヒープソートでは、この性質を用いて、ヒープから次々と最小値を取
り出し要素をソートしている。また、ヒープへの要素の追加、削除、値の変更は、
が最小値とな
ることである。ヒープソートでは、この性質を用いて、ヒープから次々と最小値を取
り出し要素をソートしている。また、ヒープへの要素の追加、削除、値の変更は、
![]() の手間で実現できる。従って、データが順次追加されたり削除される
場合あるいは配列に蓄えられる値が順次更新されるような場合に、その時点での最小
値(あるいは最大値)を見つけるには、非常に都合のよいデータ構造である。
の手間で実現できる。従って、データが順次追加されたり削除される
場合あるいは配列に蓄えられる値が順次更新されるような場合に、その時点での最小
値(あるいは最大値)を見つけるには、非常に都合のよいデータ構造である。
以下、ヒープのこうした性質を利用して、階層的なクラスタリングを高速化すること を考える。